Table of
contents
| 8.1.2010 | The year I started blogging (blogware) |
| 9.1.2010 | Linux initramfs with iSCSI and bonding support for PXE booting |
| 9.1.2010 | Using manually tweaked PTX assembly in your CUDA 2 program |
| 9.1.2010 | OpenCL autoconf m4 macro |
| 9.1.2010 | Mandelbrot with MPI |
| 10.1.2010 | Using dynamic libraries for modular client threads |
| 11.1.2010 | Creating an OpenGL 3 context with GLX |
| 11.1.2010 | Creating a double buffered X window with the DBE X extension |
| 12.1.2010 | A simple random file read benchmark |
| 14.12.2011 | Change local passwords via RoundCube safer |
| 5.1.2012 | Multi-GPU CUDA stress test |
| 6.1.2012 | CUDA (Driver API) + nvcc autoconf macro |
| 29.5.2012 | CUDA (or OpenGL) video capture in Linux |
| 31.7.2012 | GPGPU abstraction framework (CUDA/OpenCL + OpenGL) |
| 7.8.2012 | OpenGL (4.3) compute shader example |
| 10.12.2012 | GPGPU face-off: K20 vs 7970 vs GTX680 vs M2050 vs GTX580 |
| 4.8.2013 | DAViCal with Windows Phone 8 GDR2 |
| 5.5.2015 | Sample pattern generator |
10.12.2012
GPGPU face-off: K20 vs 7970 vs GTX680 vs M2050 vs GTX580
Introduction
Very recently I got my hands on a Tesla K20. Eager to see what it was made of, I selected some of my better optimized GPGPU programs and went on to gather some performance numbers against a variety of current GPUs.
Tested devices
From the NVIDIA's Kepler family, I have:
- Tesla K20. Aimed at HPC, it has 13 cores of the GK110 architecture: 2496 basic ALUs total. The clock frequency is 706MHz and the card has 5GB of ECC-enabled memory. TDP is rated at 225W. 7.1 billion transistors.
- GeForce GTX 680. This is a gaming card, it has 8 cores of the GK104 architecture which makes 1536 ALUs total. It's clocked significantly higher than the K20, at 1058MHz. On-board are 2GB of non-ECC memory. TDP is rated at 195W. 3.5 billion transistors.
Then from the NVIDIA's Fermi family, I have:
- Tesla M2050. As all Teslas, this is also aimed at the HPC market. It has 14 cores of the GF100 variety: 448 basic ALUs total. The cores run at 1147MHz, there is 3GB of ECC-enabled memory, and the board is rated at 225W. 3.1 billion transistors.
- GeForce GTX 580. Once again a gaming card. Full 16 cores of the GF110 architecture (512 ALUs) clocked at 1680MHz. 3GB of non-ECC memory, and a whopping TDP of 244W. 3.1 billion transistors.
From the AMD front I have the only current architecture relevant for GPGPU:
- Radeon HD 7970. This device has 32 cores for a total of 2048 basic ALUs clocked at 925MHz and made out of 4.3 billion transistors. 3GB of non-ECC memory and a TDP of 230W.
Test applications
The majority of transistors in any GPU today is dedicated to single precision floating point and integer arithmetics, and that is what we will be testing today. I'm not saying DP arithmetics isn't relevant, especially for the Teslas, but making a fair test case is tricky because many programs that operate on double precision floating point data actually, after compilation, perform more integer arithmetics (index/pointer arithmetics, counters, etc) than actual DP FP. Anyway, I'll tackle doubles properly some other time.
I have selected four test applications that stress different features of a GPU:
- Digital Hydraulics code is all about basic floating point arithmetics, both algebraic and transcendental. No dynamic branching, very little memory traffic.
- Ambient Occlusion code is a very mixed load of floating point and integer arithmetics, dynamic branching, texture sampling and memory access. Despite the memory traffic, this is a very compute intensive kernel.
- Running Sum code, in contrast to the above, is memory intensive. It shuffles data through at a high rate, not doing much calculations on it. It relies heavily on the on-chip L1 cache, though, so it's not a raw memory bandwidth test.
- Geometry Sampling code is texture sampling intensive. It sweeps through geometry data in "waves", and stresses samplers, texture caches, and memory equally. It also has a high register usage and thus low occupancy.
Performance
The test applications are all implemented in both CUDA and OpenCL. CUDA usually outperforms OpenCL on NVIDIA hardware, so I have selected the CUDA port for NVIDIA's devices. OpenCL is used for AMD.
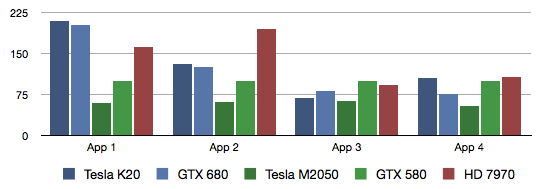
Relative performance (higher is better)
AMD is the winner here, as has been the case in GPGPU lately. While the different NVIDIA architectures perform very differently from each other, devices of the same architecture perform very predictably. Take the number of cores, multiply by the frequency, and there you go. There are differences in memory bandwidth though, especially if ECC is enabled. The Kepler architecture in general is less robust than the Fermi architecture, and its raw potential is less often fully realized.
CUDA vs OpenCL
As a bonus here I'm also comparing CUDA ports of the applications against their identical OpenCL ports. I'm not going to go very analytical on the results, because I simply don't know all the little things that eventually go differently between the two. Although OpenCL and CUDA code should go through exactly the same compiler technology, there are some differences as to how data types and operations are defined at the language level, which forces the compiler to produce slightly different code. For example, thread indexes are unsigned int (32b) in CUDA, and size_t (usually 64b) in OpenCL. Operations on such built-in variables in OpenCL get compiled into more 32b integer operations than in CUDA, and register usage might also increase (affects occupancy).
Anyway, even though there should generally be no major differences in performance, there sometimes are. Over the years CUDA has performed quite solidly, but OpenCL's performance has varied from driver version to the next. For a long time CUDA was always faster, but that is not true anymore. Anyway, in the following I have ran the 4 applications as OpenCL and as CUDA on the two Tesla cards. The setups use CUDA 5.0 and driver version 304.60. Both CUDA and OpenCL here use 32b addressing, so pointer arithmetics should compile to an equal number of instructions.
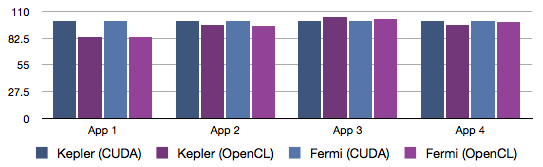
Relative performance (higher is better)
With the latest drivers, the performance difference between OpenCL and CUDA is the smallest I have ever seen. Only in the first application there is any significant difference, where CUDA is 19% faster. Of course, performance is not the only difference between the two GPGPU APIs: CUDA exposes NVIDIA specific features that are unavailable in OpenCL. These include the ability to configure the L1 cache split (can be a major advantage for kernels that rely heavily on transparent caches), vote functions (which can be emulated in OpenCL via shared counters, but this incurs a performance penalty), shuffle and some native instructions (e.g. sincos()), and so on. Also, there can be huge differences in how (non-native) math library functions are implemented.
Comments
23.1.2013
It's fun to see AMD outperforming a card that is about 10x more expensive. For integer, AMD is unbeatable on my front, but I've heard that on floating point (especially with doubles) NVidia is much better. It would be very interesting to know what the AMD & NVidia kernel analyzers say about ALU&FPU utilisation for these tests. It could be easy to carry out (since you already have the code&HW anyway) and the results would say a lot, I think.- Mate Soos
15.6.2013
Great review that confirms what I have observed myself. It is the good time to convert your apps from CUDA to OpenCL in order to animate the GPU manufacturers competition.- vic20
18.2.2014
Awesome review! I happened to have tested GTX 650, GTX 640 and GTX 580 with both CUDA and OpenCL in my Bayesian MCMC analysis, which involves double precision floating point calculation. Basically the two architectures are side by side, with CUDA slightly outperforming in a few more situations. Not surprising since they are all Nvidia devices. Meanwhile I tried OpenCL on Intel HD 4000 (which comes with i5-3570K CPU). It surprised me. I'm thinking if I should go and get a pair of HD 7970s when the price is back to normal.- Qiyun Zhu